- Unit testing comprises one dimension, where programmers test their code with all their might and tools (boundary, failure, code coverage, etc.). Unit testing is done continuously by programmers as code changes.
- The second dimension is component testing. Large systems are comprised of a collection of components that deliver different areas of functionality (reporting, messaging, data translation, etc). Component testing is done to make sure each component meets the terms of its interfaces to provide its area of functionality. This testing usually takes place after the completion of coding for each component and is done by technically skilled testers / programmers.
- The third dimension is system testing. This is black-box testing using real end-user business scenarios for test cases. Test cases are created for each path described in the system's use cases (one user, one sitting variety). Additionally, long running test cases are created that take system objects (customer, product, document, etc.) through their life-cycles (multi-user, multi-sitting variety). This testing usually takes place after the components are assembled together and is best done by business end-users.
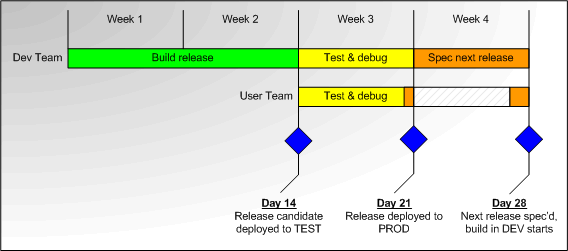
Lesson learned: For the most efficient delivery of non life-critical systems, test systems in increasing levels of scope where each level tests a different dimension of the system.